背景
我司mysql,最早部署在物理机上,做的是1主2从,40核150G*3顶了所有业务两年。
最近云平台做了高可用的集群,新业务全部在云平台上。
随着云平台的慢慢完善,物理机部署方式慢慢显示出他的不足。
- 不再重点维护,只能保持现状
- 无法实时监控慢查询,每次都需要找dba导出
- 不支持高可用
- 后续数据库优化也只会在云平台上进行
我们近期出了多次故障,主要是以下问题导致的
- 不小心写了个大批量的循环查询
- 高频接口写了个小慢查询,没做缓存
- 低频接口写了个大慢查询,管理员多点了几次
- 更新大表字段,导致主从延迟一小时,影响业务(类似于pt-online-shema-change的机制,所以放心的在线对大表进行变更)
- 更新大表字段,主库完成,同步到从库的时候,卡在alter,导致从库数据不更新
物理机模式,监控不全,导致我们排查问题严重依赖于DBA,故着手将数据库迁移到云平台
部署架构变迁
公司成立刚两年,号称线下手机回收量行业第二,但其实目前系统压力也不是太大。
正常落到数据库的qps就几百,业务读多写少。
mysql部署架构经过了几次小变化。
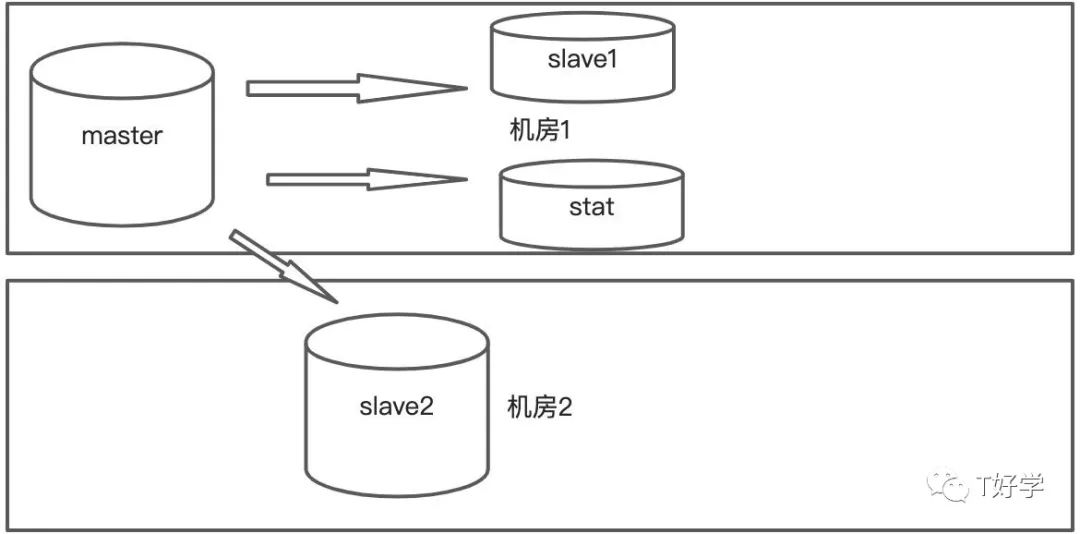
跨机房主从
- 业务在机房1,机房2各部署一套,机房1出问题了,启用机房2。
- master到slave1、slave2是严格的主从同步,10个库,每个库使用不同的账号连接,故不支持关联查询。
- 为了方便关联查询,将master中不同库的表同步到stat的同一个库中。原始数据出来后的结果也放在stat库中
- 业务做读写分离,大量报表之间读从库
- 简化架构,隔离报表业务
跨机房多活,早期体量小,根本用不上,即使用上了,因跨南北机房延迟,系统也是各种报错,无法使用,故将机房2下掉,真正有需要之后再做跨机房多活。
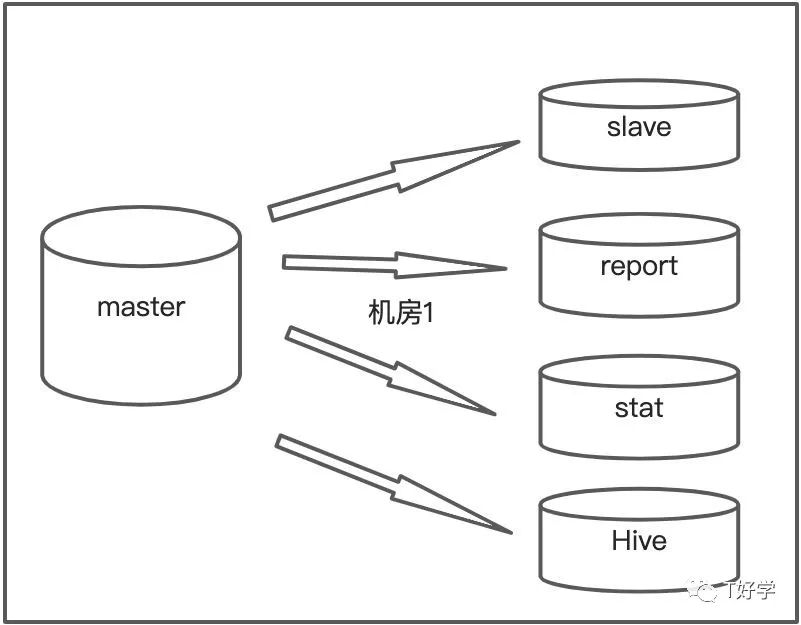
报表服务有大量慢查询,读的是从库,经常导致从库崩溃,也没时间安排去做sql优化。于是架构有了以下小调整:
- 新增hive做离线计算,慢慢把mysql不擅长做的事情,给迁移出来
- 增设report库,专门用作报表查询,慢慢优化,优先写业务代码
- 主业务还是走master、slave做读写分离
报表挪出去后一年多,系统再也没有因为管理员操作导致崩溃。
- 迁移到云平台做高可用
部分业务为了读写分离而读写分离,导致业务严重依赖于从库的实时性,出了几次主从延迟的故障之后,我们大部分业务切到了主库,只有部分不受延迟影响的才走从库。
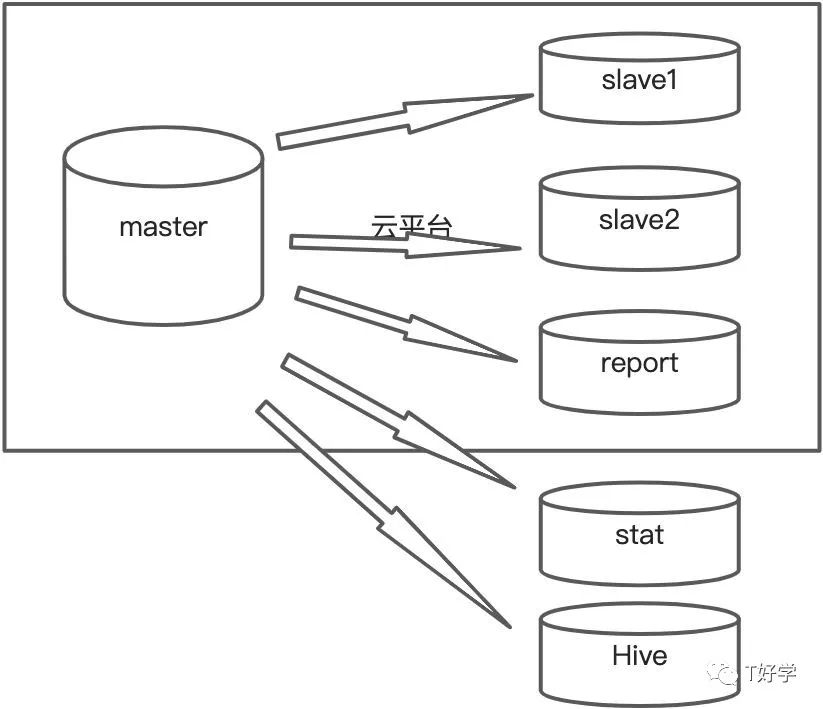
迁到云平台后:
- 使用vip进行数据库访问 vip:3306访问主库,vip:3307访问salve1、slave2。
- 主库故障,slave1或slave2自动提升为master
- report不自动切换,继续爱挂挂
- stat通过主vip的binlog进行数据同步
- hive通过vip从库进行导入
迁移方案
相关组件
- master_old
- slave_old
- report_old
- stat
- master_new
- slave1_new
- salve2_new
- report
- Hive离线计算
新建云数据库
- master_new同步到salve1_new、slave2_new、reprot
- 使用master_old的备份同步master_new
- master_new订阅master_old的数据,并设置为只读
- 等待master_new数据追到最新
切换Hive的数据源到主vip
切换stat库的同步
- 停掉stat的同步服务,查看停止的位点piont_old
- 找到point_old在master_new的binlog中对应的新位点(master_new的binlog是从新算的)
- 将stat库的源设置为master_new,并从point_new开始同步
更改应用配置
- 切换应用配置的ip为新ip
- 从vip3307,重启验证
- 主vip3306,不重启
停止master_old写入
等待master_new同步到最新
开启master_new写入
重启应用服务
迁移影响面(分钟级)
- 晚上11点之后,用户数少
- 这是我们第一次做迁移,跟DBA不在同一个地方办公,当时DBA大佬说他们切换预计要停机10分钟,应该是往最大了说。。。实际每个操作都很快,主要时间花在沟通上。
- 切换期间所有读服务正常
- 系统异常时间从master_old停止写入,到服务重启完成
所以最优的操作是,停止mater_old的同时,重启所有应用服务,这样受影响的时间,几乎等于服务重启的最长时间,大概在一分钟内。
我们可以做的更好(秒级)
我们对微服务做了分层api、biz、core,总共三十几个,有十几个底层服务对10个mysql库有数据库操作,并且全部都是dubbo服务,每个服务最少部署三个实例。
更优的操作方式:
- 对dubbo服务配置,只有主库能写入成功,才运行注册服务
- 改完ip配置后,每个有数据库操作的服务都扩容3个实例
- 等启动的实例,开始不断尝试连接数据库了,停止master_old写入,并稍等同步完(毫秒级),开启master_new写入。
- 停止所有旧实例
这样,故障时间=master_old停止写入到dubbo注册成功,看手速,大概就一两秒吧
我们还能更好(百毫秒级)
我们只有两个数据库大集群,业务库(10个database)、统计库。
开始体量少,无所谓,慢慢开始不同业务起来,代码随便写渣一点,容易相互影响,故需要准备慢慢地对各个库进行进一步隔离。
因为用了vip,我们下次迁,应该会更平滑,毫秒级故障感觉是能达到的。
从业务库把订单库抽出来,以此为例,为了简单,假设只有主库
master_old 对应vip_old
master_new 对于vip_new
- 新建库master_new
- master_new追上master_old
- 新建vip_new 指向master_old
- stat、Hive操作类似之前的
- 应用配置,全部改成vip_new,重启生效
- 停止master_old写入
- 等待master_new追上数据(毫秒级)
- 开启master_new写入
- 将vip_new指向master_new
- 验证没问题后,把master_new中非订单相关的库删掉
这样,故障时间=停止master_old吸入 到 vip_new指向master_new,操作没问题的话,应该是能实现百毫秒级故障切换的。
百毫秒级操作,待验证,有问题,欢迎指出