背景
大部分业务的QPS都会存在周期性特征,比如:
- 秒杀在秒杀开始的几分钟流量比较高,
- 办公系统只在白天上班时间才会有流量
- 自建电商,在直播开始的时候,比较多人购买商品
在这些场景下,需要在适当的时候,对系统进行扩缩容。
需求分析
假设系统都部署在AWS的EC2实例上,常规的扩缩容做法是,在需要的时候,在EC2列表中,手工选择实例进行启动或停止操作,比较繁琐。
故期望提供一种基于EC2标签的方式,对EC2进行批量控制。
方案
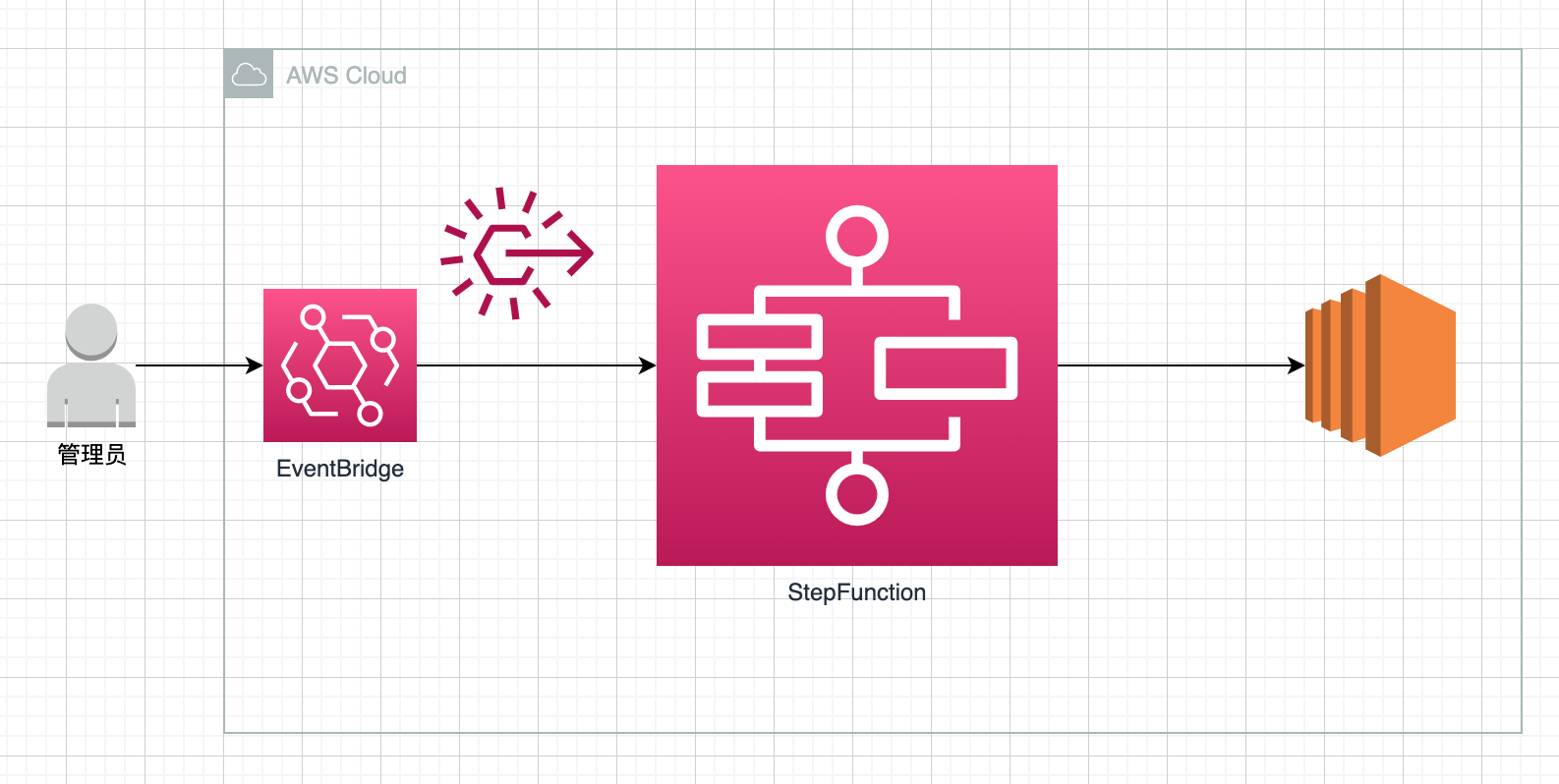
为了方便配置,根据扩容时长不同,做了两个不同的调度方案,整体架构是一样的
- 短时间扩容,然后缩容,如:每天8点到19点整点扩容3分钟,然后缩容。只需要配置一个EventBridge
- 长时间扩容,如:每天8点扩容,19点缩容。需要配置两个EventBridge,一个启动,一个关闭
管理员配置基于crontab时间触发的EventBridge
EventBridge触发对应StepFunction的调用
StepFunction处理标签识别,并对EC2进行控制
长时间时间扩容方案
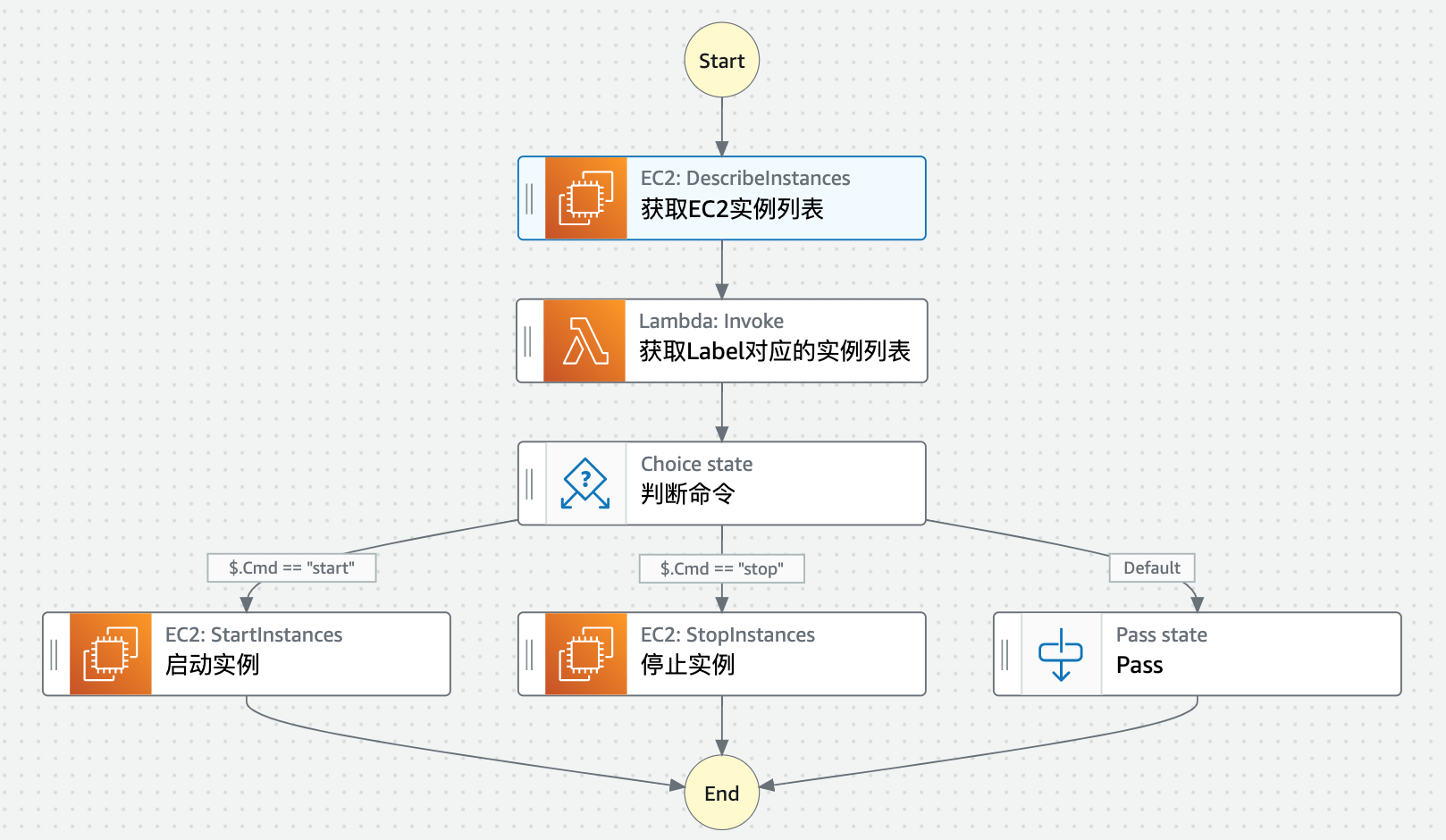
- 定义StepFunction的能力,支持调用方指定是启动还是停止
- 获取EC2实例列表,传入参数 MaxResults 配置为100,这里假设EC2实例数量不超过100
- 调用 filter_ec2_by_tag 函数获取实例Id列表
- 根据EventBridge传入的Cmd参数执行启动或者停止实例操作
EventBridge配置
启动 Cron 表达式
1
0 8 * * ? *
启动 入参格式
1 | { |
停止 Cron 表达式
1
0 20 * * ? *
启动 入参格式
1 | { |
filter_ec2_by_tag 函数代码
1 | exports.handler = async (event) => { |
指定命令扩缩容状态机
1 | { |
短时间扩容方案

获取EC2实例列表,传入参数 MaxResults 配置为100,这里假设EC2实例数量不超过100
为了方便传参到下一个步骤,加了两个Pass组件做参数转换
调用 get_ec2_instanceIds_by_tag 函数获取实例Id列表
- 为了方便支持多标签,这里只判断Value相对,就会被匹配到
支持启动指定实例id的EC2,然后等待指定N秒后,再停止实例
这里管理员只需要配置EventBridge
EventBridge配置
Cron 表达式
59 7-19 * * ? *
因流量是整点开始,这里提前一分钟开始启动实例
入参格式
1 | { |
get_ec2_instanceIds_by_tag 函数
1 | exports.handler = async (event) => { |
短时间扩缩容状态机
1 | { |
运维人员操作说明
- 先预创建备份EC2实例
- 给需要扩缩容的EC2实例配置指定的标签,如 ScaleLabel=xxx
- 按前面的说明配置EventBridge的cron表达式及调用入参
架构说明
- 可运维
- AWS完善的日志监控告警,方便服务调试,故障排查
- 可视化运维配置
- 可视化执行逻辑
- 高可用
- 依赖于AWS的高可用服务,自定义部分不存在性能问题
- 可扩展
- 以StepFunctions的方式进行实现,支持可视化调整业务,比如程序启动之后,通过sns通知干系人等
- ec2:describeInstances 组件,在文档中支持Filter参数,可直接一步到位过滤出指定标签的实例,但在调试的过程中提示不支持Filter参数,后续aws支持了,可把参数给加上
- 为了少写写代码,这里使用了ec2:describeInstances 组件,目前是查出所有实例,在少量实例的情况下可以接受。如果实例比较多,该组件可以方便的替换成lambda函数,调用EC2对象,通过Filter参数直径过滤出可用的实例
- 短时扩容服务状态机,可支持后续业务代码,根据实际需求进行简单的调用,应用场景非常广泛
- 低成本
- 全流程使用Serverless,因调用量低,可以认为无任何云服务成本开销
- 安全
- 全链路通过IAM进行授权调用
- 不对我暴露任何接口
- 高性能
- 不在本方案的考虑访问内